What is a Web Spider?
Indexers ( also known as dumb spiders ) require simple logic to operate and not much input other than a
URL to start from. The spider starts on the given
URL, parses the page like a browser would, locates and returns the available links and repeats the process.
Along the way, URLs are logged for indexing. Any data that can be matched for collection can be saved.
A common thing to do is log all URLs the spider visited and their return code to
a database. This way, you can see all available links on a website and
their availability to an end user.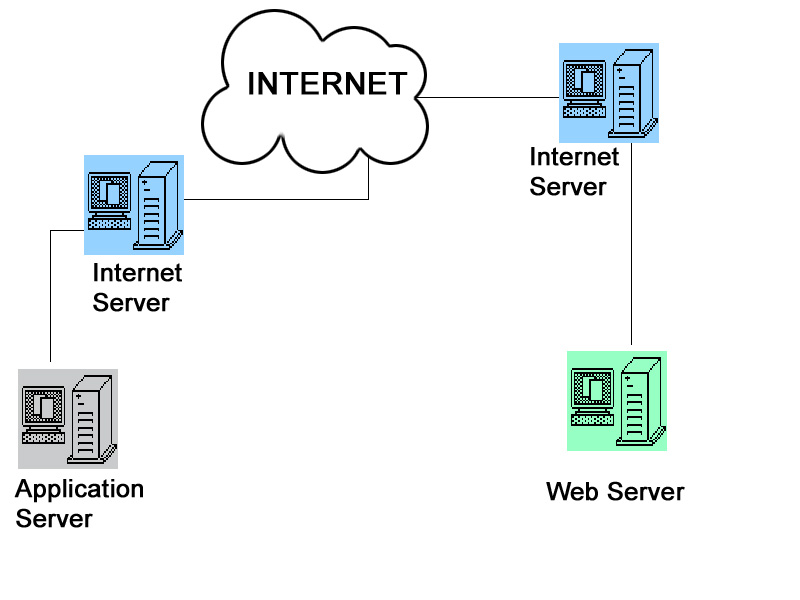
<prev | next>